使用性能极差的笔记本挂机在Colab上训练模型
很早就听说谷歌有可以免费使用的gpu,但是一直不太相信,因为这东西毕竟太贵了,自己买都买不起,怎么还会有免费送的呢?但由于实验室的GPU不够分,在同学的推荐下,尝试了一下,em…真香。
先送上地址:
(当然,你需要一个梯子才能友好的访问,并且,为了方便上传和下载大量数据,这个梯子的质量还得够好)
Colaboratory 是一个免费的 Jupyter 笔记本环境,不需要进行任何设置就可以使用,并且完全在云端运行。Google Drive 是免费的云盘,大小为15G(可以付费升级)。将数据和代码上传到Drive上,就能在jupyter中方便的加载和调用。两者配合起来使用与在本地使用没有多大的区别。
入门教程可以参考官方的例子,给的非常详细。
一些特点
- 程序运行时不能关闭浏览器的jupyter页面,如果网络连接中断的时间过长,也会导致训练停止。有一点令我很疑惑,在训练模型时,本地浏览器(chrome)也在执行复杂的计算任务,有时候cpu使用率直接超过100%,导致我用来挂机的surface直接报警…讲道理计算的任务是由GPU完成的,浏览器只是获取实时的状态,那浏览器到底是在做什么任务导致了这么大的CPU和内存消耗?
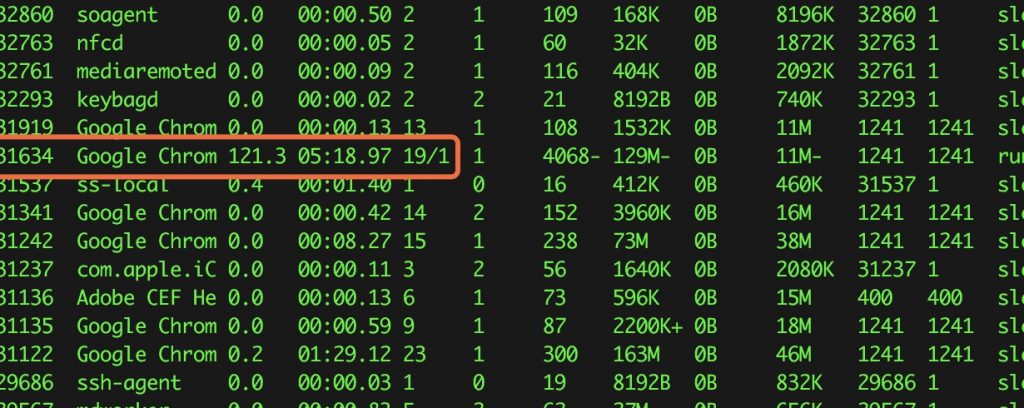
- 刚开始使用时,分配的GPU是Tesla T4,显存14221M,已经能胜任很多任务了,但是如果经常用它挂机运算,能分配到的显卡配置就会降低,我现在能使用的是Tesla K80,显存10805M(不知道还不会继续降低…)。参考为什么我无法使用 T4 GPU 等硬件资源?
若想优先使用最佳可用硬件,用户需交互使用 Colaboratory,而不能将 Colaboratory 用于长时间运行的计算。如果用户将 Colaboratory 用于长时间运行的计算,可能会在以下方面暂时受到限制:可用的硬件类型和/或硬件可用时长。对于有较高计算需求的用户,我们建议搭配使用 Colaboratory 界面和本地运行时。
请注意,我们绝对禁止使用 Colaboratory 来挖掘加密货币,这样做可能会导致用户完全被禁止使用 Colaboratory。 - 长时间训练模型时一定要经常清回收站,Google Drive 只有15G,并且它被覆盖或删除的文件都保存在回收站中,并没有真的删除,需要手动清除,如果15G满了,会出现各种错误!
- 在选择GPU/TPU加速时,要在 “修改”–>”笔记本设置”中手动进行选择。

- Google Drive中的文件更新之后,Colab中加载的文件会有延迟,不会立即更新,可以多点下刷新。
踩坑经验
- 报错:
ImportError: libcublas.so.9.0: cannot open shared object file: No such file or directory
这是由于tensorflow版本与cuda版本不兼容导致的,在colab上,出现这个问题的原因可能是在同一个notebook里切换了tf的版本,导致了第一次分配的gpu与后面不一样。所以重置一遍notebook就行
解决方案:选择“代码执行程序”–>“重置所有代码执行程序”。如下图:
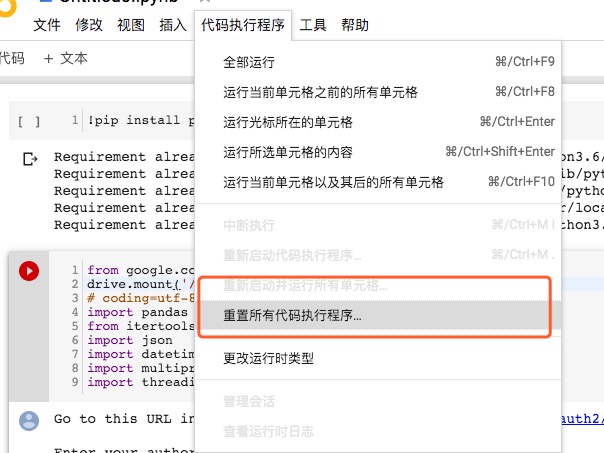
- 在使用TPU加速时报错:
Error recorded from training_loop: File system scheme ‘[local]’ not implemented (file: ‘XXXX’)
这是因为TPU不支持从Local file system里读取文件,连Google drive也不行,只支持Google Storage上读取数据。 而Google Storage虽然可以对新用户免费送300美金,但是这个新用户激活时没有“中国”的选项,因为要填Visa卡验证身份,所以大家如果没有境外的visa卡,就不用再尝试了。
另外,jupyter中可以通过下面的指令查看TPU_Name
!echo $TPU_NAME
- 程序跑着跑着就挂掉了,没有任何提示??
我遇见过两种情况,一是最常见的,网络中断了,那么恢复网络连接后就能看到程序仍然在执行;二,Google Drive的挂载断了,需要重新挂载Google Drive,这个时候只能重新运行程序….如何区分这两种呢?刷新一下网页,确认网络正常的情况下看程序还有没有继续跑,如果有,就是好的,如果没有,就重新挂载google drive吧。也可以看左边的“文件”,如果还能看到Drive,就表示挂载正常,如果看不到,那就gg了

- 在线解压中的问题
经测试,在线解压工具对于大文件(上1一个G的),几乎不能解压成功。几百M的文件偶尔成功,几十M的文件成功率很高。所以对于大文件,最好还是在本地解压之后再上传。
使用Colab运行有复杂文件结构的项目
Colab 提供的jupyter-notebook是单一的脚本文件,但往往我们的项目里有多个文件,可能有几十个class在互相import,所以我们怎么才能像在本地执行项目一样在colab上运行程序呢?
说起来也很简单,将所有代码和数据上传到Google Drive中,把jupyter当作命令行工具来用,输入 !python xxxx(xxxx表示入口程序,感叹号!一定要写,表示输入的是命令行)。
但是需要注意:
- 1.云盘根目录是 “/content/drive/My Drive”,这里有个空格,在输入命令的时候空格要加转义\。比如:
!python /content/drive/My\ Drive/BertNer/BERT_NER.py
- 2.import 时出现如果出现类似下面的报错:
ModuleNotFoundError: No module named ‘XXXX’
解决方案:将项目根目录添加到环境变量中:
import sys cur = '/content/drive/My Drive/XXXX' sys.path.append(cur)
注意这里的”My Drive”空格不要加转义
- 3.可以使用ShiftEdit等在线编辑器对云盘中的代码等文件进行修改,但是文件保存之后不会立即更新到Google Drive,有一个缓冲的时间。
与Google Drive 配套的在线编辑器
结尾
现在人工智能大热,Colab的用户数量肯定不小,谷歌能承担这么大的一个开支,只能说——业界良心!而让我惊讶的不仅仅是免费的GPU,还有这配套的开发者服务,与jupyter无缝衔接的Google Drive、Google Storage, 以及在线编辑器、在线解压等小工具,几乎覆盖了一个机器学习开发者需要的一切。这些服务很难从用户上赚到钱,但是从长远来看,这为整个业界实实在在的培养了一大批从业者。在这一点上,不得不对这个公司充满了敬意!
点击量:21935